I feel like there are a couple threads in here, and I need to check whether I’m on the right track.
When you say ‘being able to save the balance state’, do you mean keep it in some sort of persistent memory so that the agent doesn’t have to keep recalculating it every time it needs it?
In this scenario, it sounds like your big concern is correctness of balances vs multiple function calls changing state in parallel. Is that true?
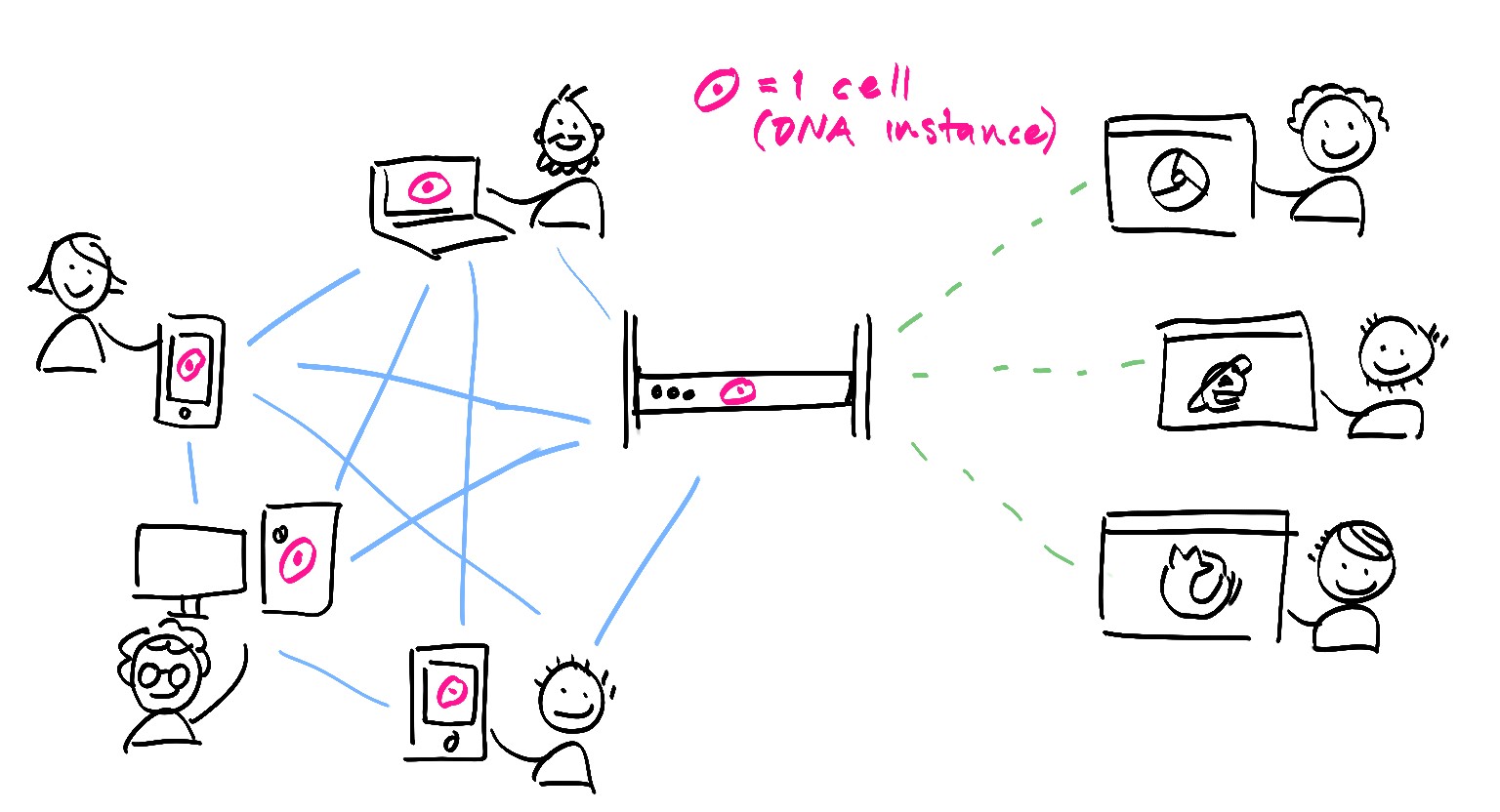
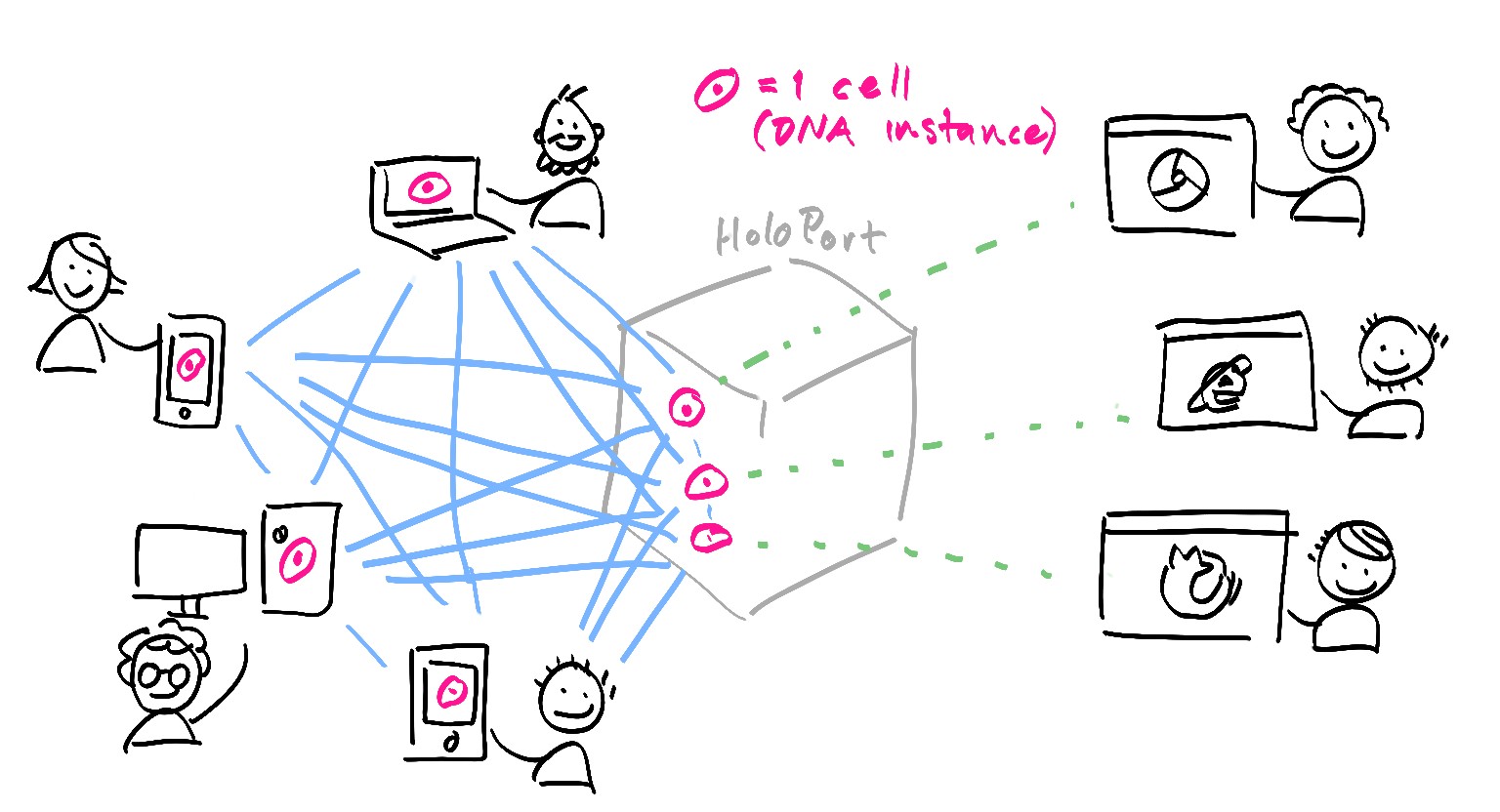
Because I might miss your response, I’m going to give a pre-answer assuming that I’m right  It’s best to look at a source chain as a journal of local state changes from which you can reconstruct a full state at any point (like a write-ahead log in a relational database). This should mean that you can cache the reconstructed state in-memory (in your case the balance) and just keep applying the changes to the state as they come in and are committed.
It’s best to look at a source chain as a journal of local state changes from which you can reconstruct a full state at any point (like a write-ahead log in a relational database). This should mean that you can cache the reconstructed state in-memory (in your case the balance) and just keep applying the changes to the state as they come in and are committed.
As you’ve probably already discovered, there’s no persistent memory between zome calls; the only way you can persist anything is as a source chain entry, or in your front-end (e.g., GUI) somewhere. Either of those might be viable options…
Could you tell me more about the UTXO model you’re using? I’m only familiar with it in either a blockchain context, where there’s only one ledger to worry about, or an R3 Corda context, where each chain of UTXOs has its own history and is passed around peer-to-peer with each transaction (and validator pools are used to prevent double-spending).
As for having three simultaneous RPC calls, I presume you mean that they’re all called at a certain point and could see the same source chain state, which means that whichever call writes first will ‘win’ and the other two calls will see an incorrect state. Is that what you’re concerned about? If so, I don’t know how Holochain currently handles it, but with some refactors we’re working on, each zome call will run in its own transaction space. If call A starts, then call B starts, then call A modifies the source chain and finishes, then call B tries to do the same thing, call B will return an error, similar to trying to write to an SQL table that has a write lock on it. This prevents inconsistent state from concurrently calling functions that write to the source chain.
Hope this helps; ask as many questions and make as many corrections as you like!