
Jamison Day would be another good guy to bring into this conversation, but sadly he’s not on the forum (yet). When we were discussing this in the internal MM, he was concerned that allowing bidirectional bridges would create circular dependencies that (if not managed correctly) could trigger an infinite loop of new entries being created in response to other entries being created. To my mind, though, that risk already exists between zomes and even within a zome. It does require discipline to prevent this sort of thing.
I’m also pretty fond of the programming paradigm based on signals, and YES, it does feel very Ceptr-like. Very much ‘receptive capacity’/yin/etc and all that. Also makes me think of functional reactive programming, which is touted as a way to get a grip on knock-on effects because it’s all about one-way data binding (although you can definitely create infinite causative loops there too).
Hmmmm, signal-passing as a way of propagating data across bridges. This is an interesting line of inquiry. Here’s what popped up for me:
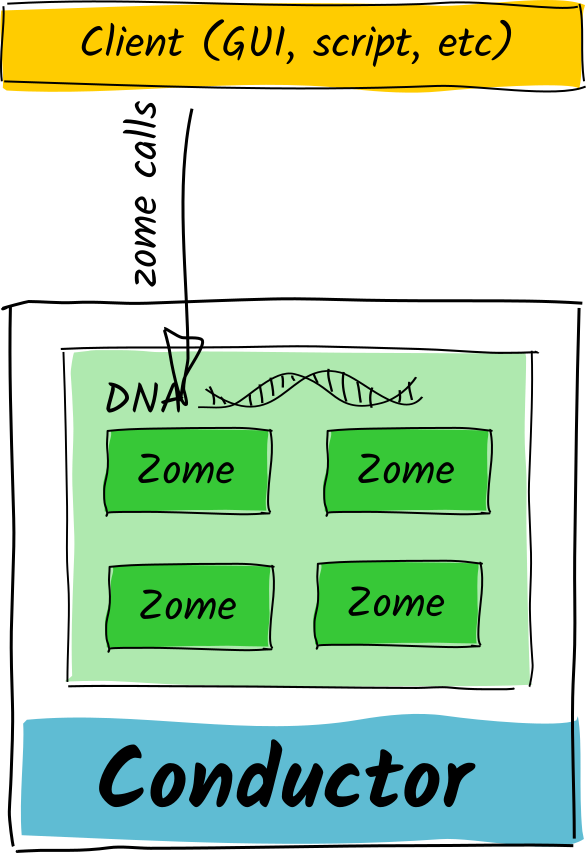
A client and a DNA have a conversation with each other with a pair of channels. One of them, zome calls, is active/direct/yang: the client directs the DNA to do something.
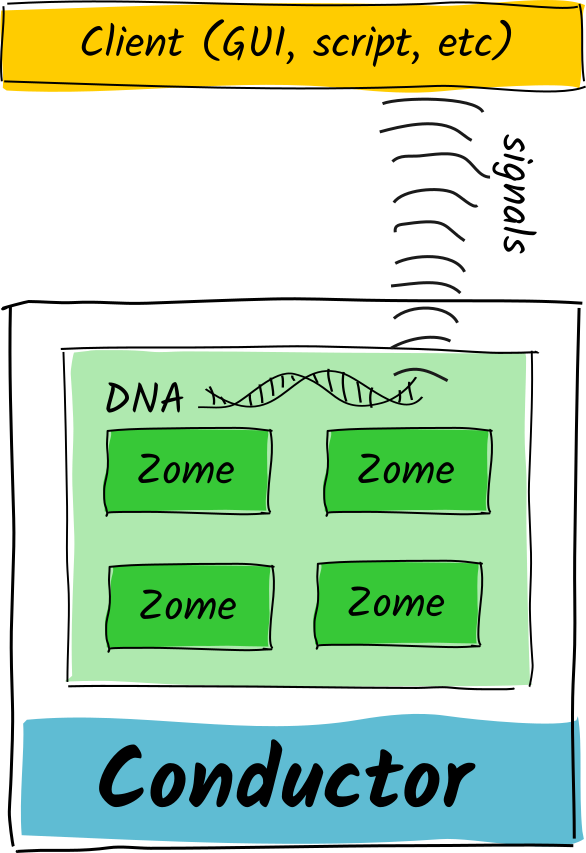
The other, signals, are passive/diffuse/yin: the DNA is informing rather than directing. There’s no dependency on the client; in fact, the DNA doesn’t even know/care if a client is listening.
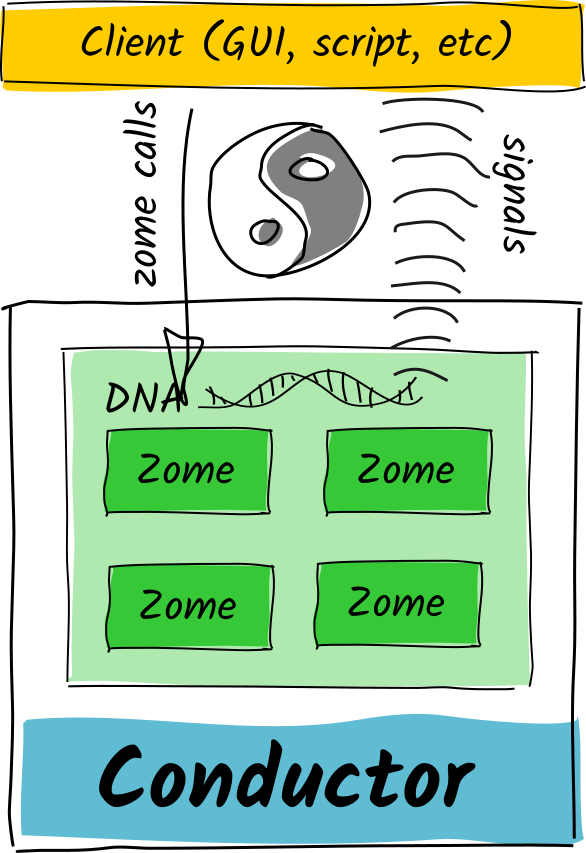
So now we’ve got this nice duality, yin/yang, passive/active, diffuse/direct, a nice normalisation that creates a control flow without circular dependencies.
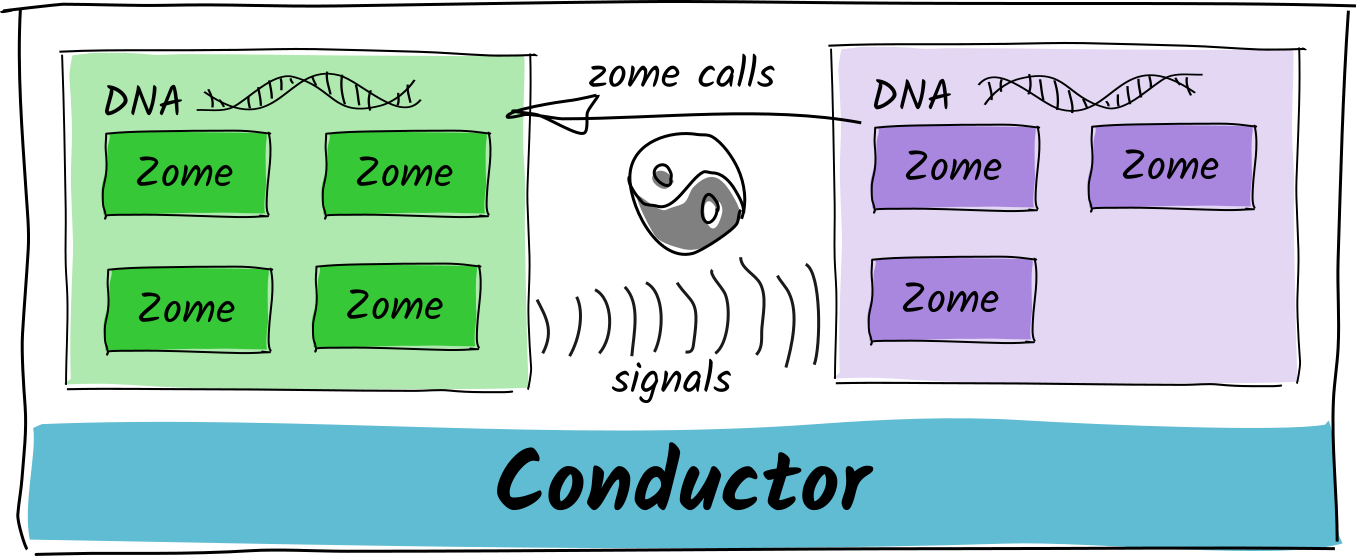
Hmmmmm… what other thing acts as a ‘client’ that can make zome calls?
Well how about other DNAs via bridging?

We probably want to avoid explicit circular dependencies among DNAs too. So what could we use to get two-way communication between DNAs and still keep the dependency graph clean?


 I wasn’t thinking of closures when I wrote that up. I was thinking about that immutable, category-theory style that FP encourages — data structures are just dumb objects with no internal state, and state mutation involves mapping/reducing/filtering on data structures and the monads that hold them, to produce new data structures.
I wasn’t thinking of closures when I wrote that up. I was thinking about that immutable, category-theory style that FP encourages — data structures are just dumb objects with no internal state, and state mutation involves mapping/reducing/filtering on data structures and the monads that hold them, to produce new data structures.