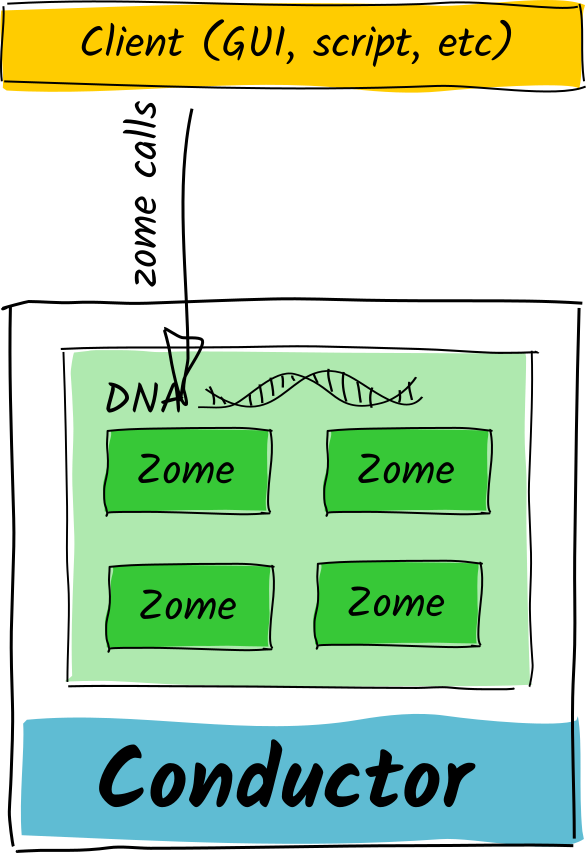
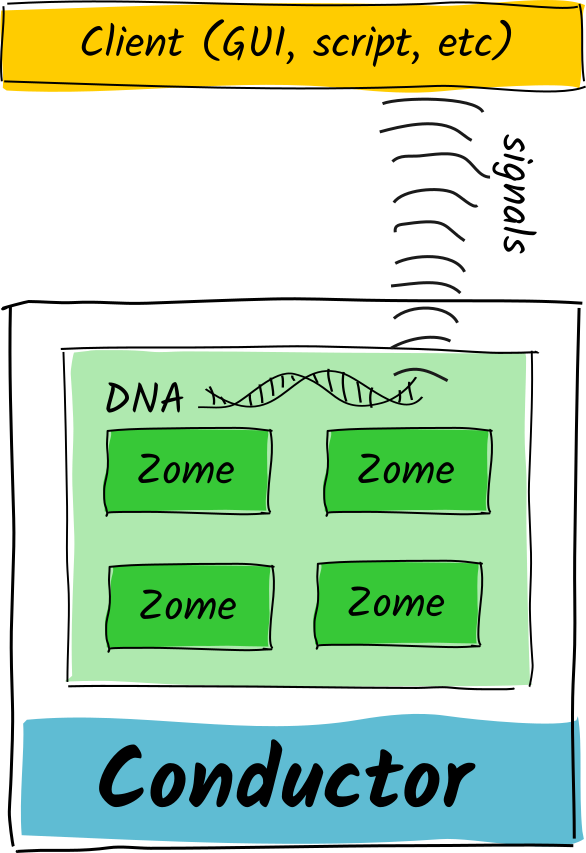
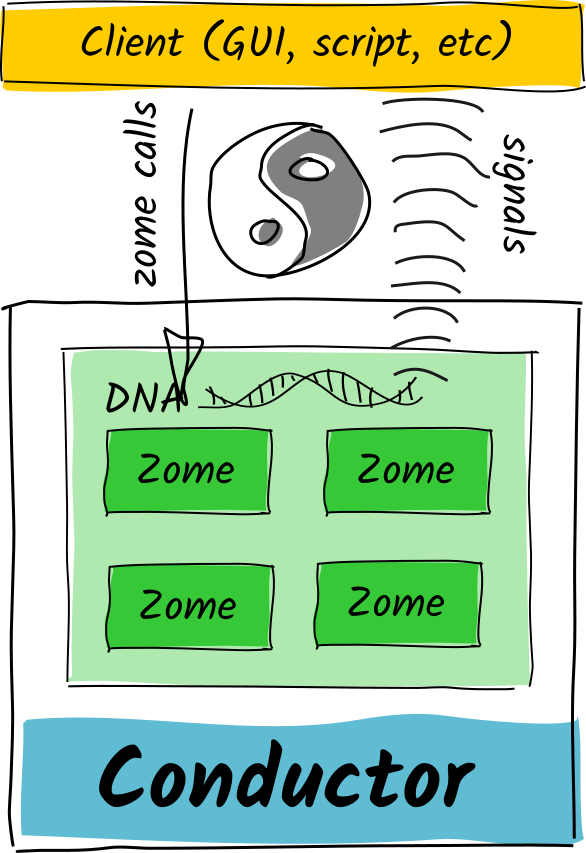
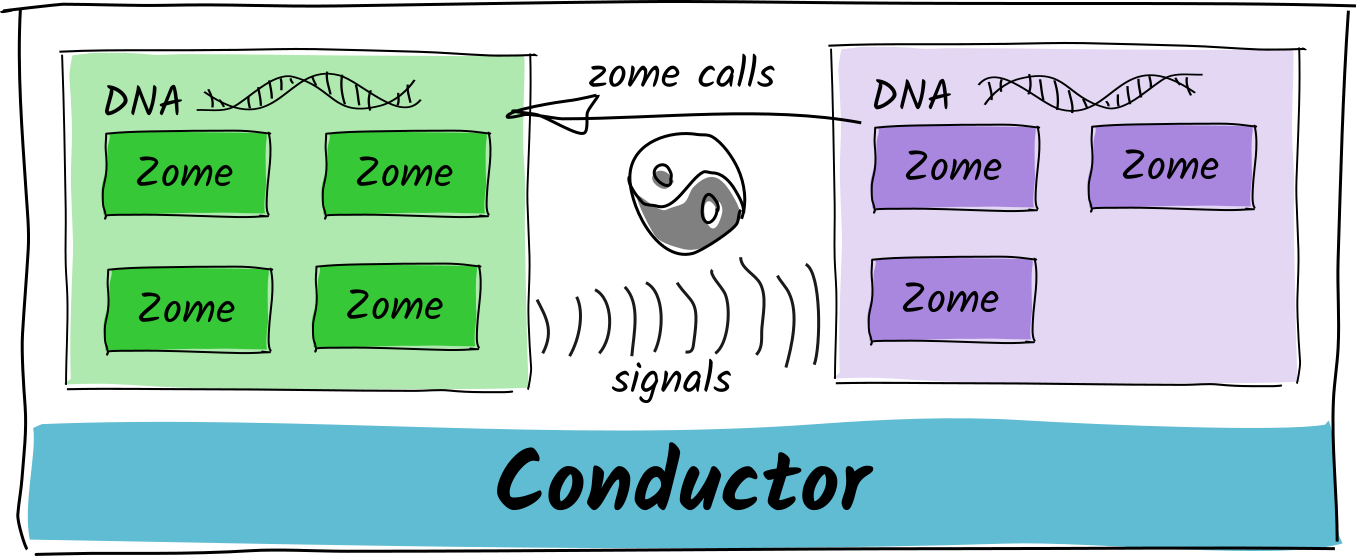
@ViktorZaunders yeah, that’s exactly the concern that one of our team members raised. Reasoning about two mutually interdependent DNAs is moderately easy, and so is reasoning about three if you wrote them all. But once you have an ecosystem of developers and their DNAs, you could run into circles with unintended consequences.
@pospi
you can?! Wow, I didn’t realise that — it feels like leaky encapsulation to me. Wonder if that was just an oversight and it’s gonna get closed in the future…
Back in my programming days, I used to fret and obsess about circular dependencies. In fact, they were impossible cuz I was writing in C#. Made for some convoluted ways of getting the dependency graph untangled; dependency injection was usually my go-to.
Thinking about it, ambient signal emission doesn’t prevent this either. DNA X could emit signal A that causes DNA Y to take action and emit signal B that DNA X receives, causing it to emit signal A again. It was just my proposal for a way to un-circular-ize hard DNA dependencies in a tidy way. Ambient/declarative/passive signals allow a DNA to be ignorant of its consumers, whereas direct/imperative/active calling/message-passing introduces tight coupling because it requires the caller to know how its callees work.
I’m chewing over your thoughts on signalling, message passing, and validation @pospi. Raises interesting thoughts. Re: validation, I see the value. It could be ensured just as easily with emit as with call, I think, because my conductor can provide assurances that the right DNA emitted that signal.
Re:
Definitely see what you’re saying there. Looking for the base abstraction, call could certainly be seen as a special case of send with a method name and tuple of arguments as its message.
And within one conductor, that’s pretty much how it works — the conductor creates a special public grant type for intra-DNA zome calls, inter-DNA zome calls, and UI calls, then gives the token to the callers. It is nice to have a special affordance for function calls layered on top of message passing though, wouldn’t ya say? 
There’s even a pattern for doing it between agents — Alice shares the cap token with Bob, which he then passes back to her whenever he wants to “call a zome function in her running instance” (which actually just looks like him sending her a message consisting of function name, parameters, and cap token). Alice checks the function he wants to call against the conditions of the grant represented by his token, then calls the function for him if it all checks out. Eventually I think this might have its own convenience function in the HDK.

 life imitates art!
life imitates art!