
So for my project Library, I need to have a node in my knowledge graph be editable and versioned, with the author of each version tracked as well. I started thinking about this over here. In this post I want to share a first attempt at a design solution and get some community feedback. None of this is implemented in code, just thought through against my understandings of Holochain’s architecture.
There are a handful of sub-patterns involved in this solution. Some may have real computer science terms that I don’t know, so feel free to point me towards them when applicable.
The components are:
- Agent
- Content
- Delta
- Governance
- Snapshot
- Version Tree Chain (bad name, please help)
Also, this might be long and rambling, so please ask as many questions as you like so that I can edit this and make it as clear as possible! This is my first stab at a decentralized design, and therefore my first attempt at explaining one 
Agent
This one is very simple, just a user, probably just their public key. I don’t think I need any other user info for this solution.
Content
This is just raw content. Probably in my case will just be json, but it could be anything in this pattern. The important part is that there is no unnecessary metadata, since we want the hash of “the same content” to always use the same DHT address for storage concerns.
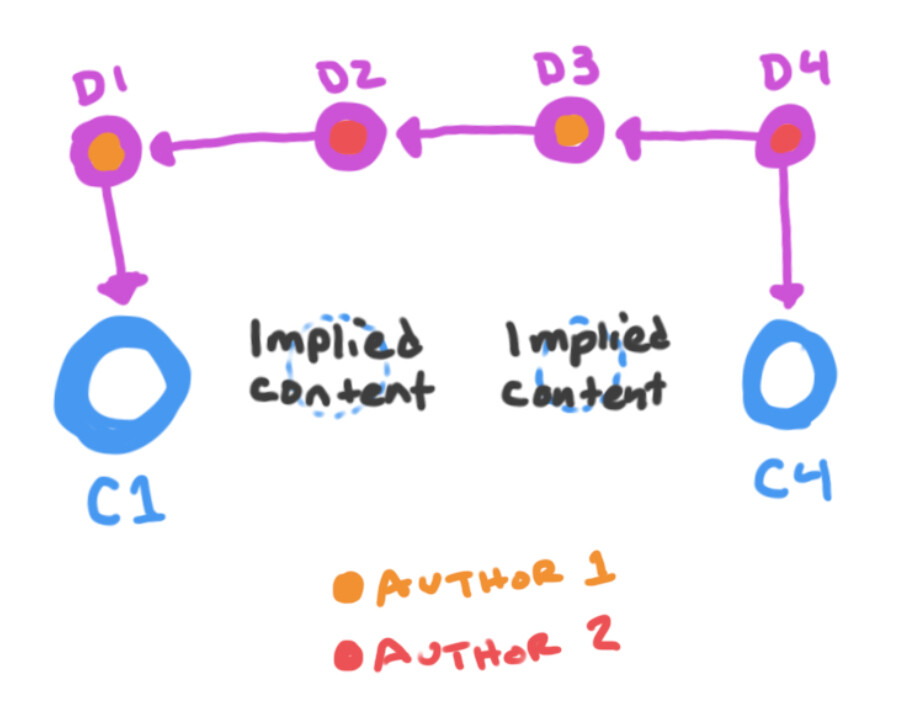
Delta
The contents of a delta is an author along with a list of changes. What constitutes a “change” is up to your implementation; in my case, probably some custom json schema for insertions and deletions. (The delta might also be able to support a list of authors if a single delta has multiple authors, but I sketch it out here with one author per delta.) The delta has a link to the previous delta in the chain, and has an optional link to a content object that represents the state of the content after the changes in that delta are applied. This means that every change does not necessarily result in a full new content object being committed to the DHT; it can be up to program logic (or even the user) when to actually create that “compiled” content object.
If you ever have a delta that does not have a linked content object, you can follow the chain backwards until you find a delta with a compiled object and then construct it from the chain of changes. In the picture below, the circles of “implied content” mean that there is a deterministic content block that can exist there, but that it hasn’t been committed to the DHT. The content being deterministic means that if we make a delta that “reverts” to a previous state, it would essentially just create a pointer back to an existing content object. This structure makes it so that we store as little data as needed on the DHT: only the small changes made between versions, and as few full “compiled” objects as is necessary for our app.
Governance
The governance object will come into play in the snapshot object. Essentially, a governance object is composed of a list of Agents, along with monotonic “voting” rules. (Unsure if I’m using “monotonic” correctly here.) The monotonic requirement is that resolving the results of a “vote” cannot change based on limited information, and that the results can not be ambiguous. For example, let’s say we have two agents in a governance object: they can not each be given 50% voting power, because then a vote can be tied. (However, maybe there’s room for failed votes? Unsure.) Another limitation would be that votes cannot be deleted or changed; if a vote was deleted and not yet propagated, another user who casts a vote may determine a decision was reached even though one of the votes is now invalid.
A user making a vote can use their local source chain to enforce they are only voting once. So in a “happy path scenario”, we have a simple 3 member system with equal votes. As soon as someone makes a vote that meets the acceptance criteria, we can be sure that a decision was deterministically reached. In that scenario, agent 1 votes for A, and agent 2 also votes for A, agent 2 doesn’t have to wait to see what agent 3 voted for, because we already know that A must be the winner.
Snapshot
Since we can never be sure that two agents don’t simultaneously make a new delta off of an existing delta, branches are impossible to prevent (and also a good thing for the user!) But unfortunately, this creates a technical problem. A snapshot is where we really get into the weeds of solving branching.
The core concept is that an individual snapshot contains a hash of a delta object, and a hash of a governance object (and also optionally a link to the content it represents). The governance object acts as permissions for the snapshot. Potentially, there may be different permissions for different actions (like different permissions for proposals vs approvals). Any qualified agent can propose a candidate for succession to the current snapshot. Any qualified agent can also cast a single vote for one succession candidate. I imagine that the votes would be stored as links to the candidates, with tags that mark it as a vote and also identifying the agent’s index from the governance object’s agent list.
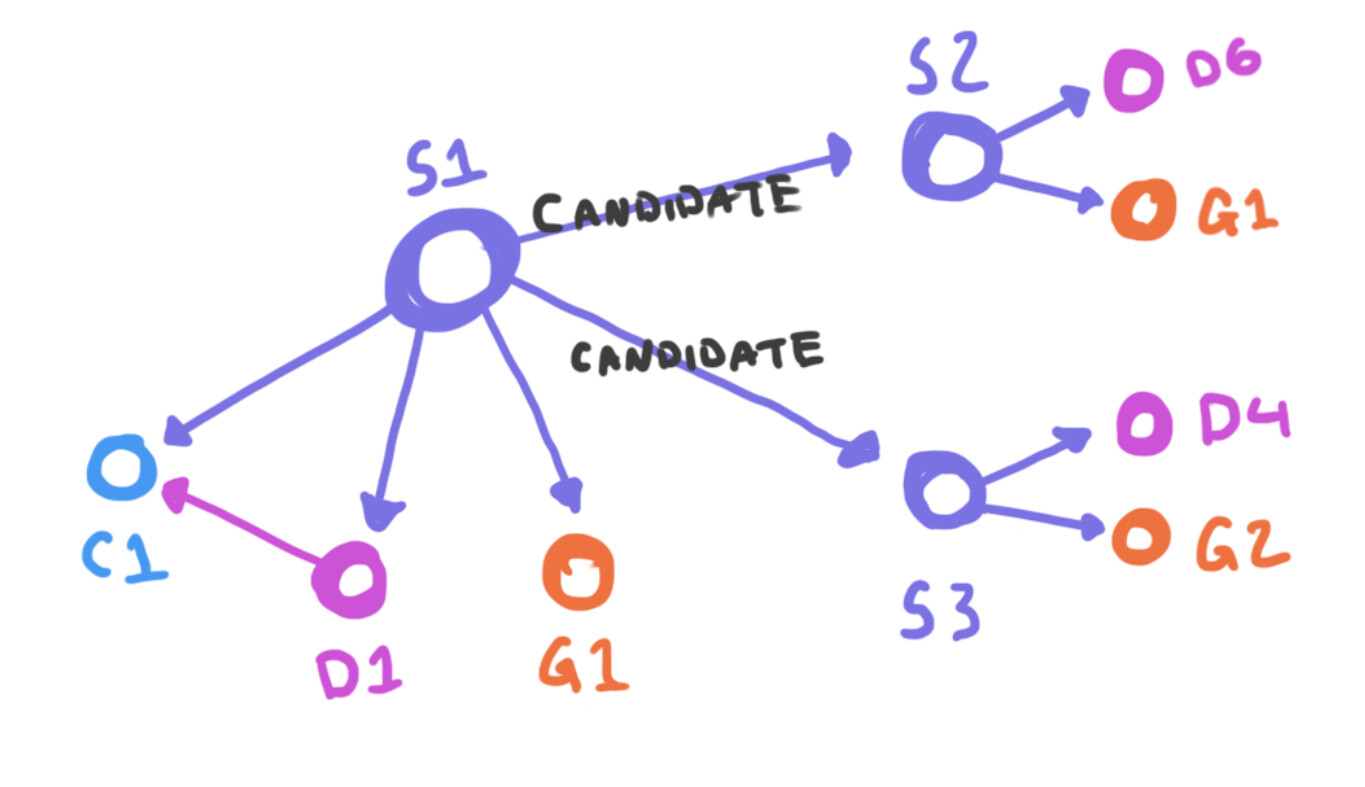
The cool part here is that since the snapshot contains a delta and also a governance object, the governance of the snapshot can change over time, by voting on a new snapshot that has different rules. As part of the validation rules for a candidate proposal, we can also ensure that the delta contained in a succession candidate contains the current delta in its chain, by navigating backwards through the new delta’s chain. (This could be optional, depending on how strict your use case is on what constitutes a “version”.) And finally, once a succession candidate is chosen, we can use that opportunity to ensure that a delta that is contained in a snapshot has a concrete content object (since we just validated that the chain is valid, we should also have all of those deltas in memory to quickly generate the content object if it doesn’t exist). We can also then link the snapshot to that content object.
So now, every snapshot points to a deltas that create an unbroken chain, and each snapshot points to a concrete content object (though this could be optional). And since all of the votes are stored as links off of each snapshot, these can be re-validated by anyone who wishes to do so. In fact, since voting may happen asynchronously, any individual vote may not reveal the winner of a decision at voting time, but might be discovered later on by someone who visited the node and saw an unresolved vote, and then checked its status. And if multiple people were to do this at the same time, the results would always be deterministic so there shouldn’t be any conflicts (I think??).
My hope is that these “Snapshot chains” would be used as a way for larger “organizations” or even highly-regarded individuals to “endorse” a certain perspective on information. This way, users can use good old-fashioned “human trust” in an institution to perform curation services on those perspectives.
This also enables branching! Anyone can take any delta and create a new snapshot from it with their own governance. This makes it possible to branch when necessary, while other mechanisms (like social ones) can encourage collaboration in the majority use cases.
The biggest issue is that I don’t know how to scale this design to “massively open collaboration”. You could enable open submissions, but you’d still have to have a reasonably small approval board for decisions to be made.
Version Chain-Tree
(Please help me find the right name for this)
Now we have one last problem. Let’s say you’re looking at a particular snapshot, and you see there is a new version (by the presence of a link to a new version on it). You can go to the next version, but you’d really like to just jump to the latest version. We could traverse those links until we get to the end, but what if it’s really long? We could also make it so that every time there is a new version, we go back through the chain and create a new link to the latest (and delete the old link to the latest), but this would scale even worse, both with link storage and also network traversal. What if an object had 100 changes? or 1,000,000 changes? Neither of these solutions scale well.
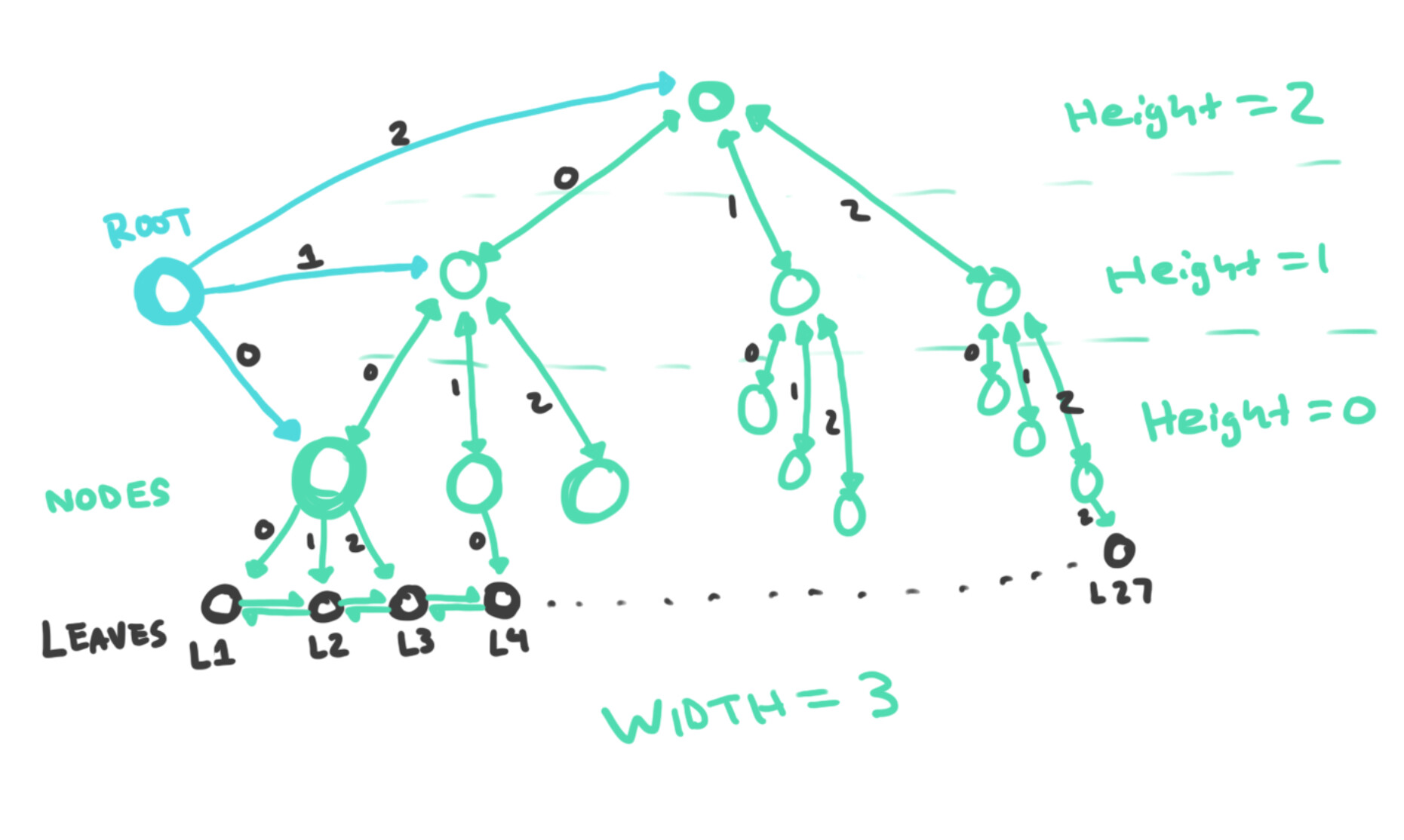
To solve this, I came up with this chain-tree structure that grows from the bottom up. There would be a “root” node of the tree, which has a width and a unique hash (I do not yet know what I should use as the source of this hash… it could just be like a hash of the hash of the first object in the chain? idk). Each “node” is composed of the root hash, along with its height and index in the tree. In the diagram, the tree has a “width” of 3, so each node has up to three children. Once a node is full, it creates a new parent by incrementing the height, and then creates a neighbor linked from the parent by incrementing the index. Every time a new leaf-object is added to a node at height zero, it creates bidirectional links for next/previous between the new leaf and the previous last leaf. The root node also creates a link to the “top” of the tree (using its index) every time a new top is created.
With this structure, any node in the tree can jump to the root, then to the top, and then follow the highest index downward to find the latest. So in the example below, with a height and width of 3, there are 27 possible versions in the tree/chain (I used 3 to make it plausible to draw; in practice this would probably be much higher). Any given leaf object can traverse through the chain with next/previous links, but also, any leaf can get to the latest leaf with 5 link traversals. With this pattern, we can choose a width that works best with a “maximum amount of links desirable for an element on the DHT”, which I would imagine is much higher than 3, and this makes a lot more sense. (For example, with a width of 64, we could store ~260k versions and get to the latest with those same 5 link hops). An alternative approach that doesn’t include this root node with a top link would be to just recurse up to a parent node until there is none, and then follow the highest index down. Either way would be fine I think. You’d have localized forward/backward traversal for any version in the chain, as well as an easy way to jump to the first and last leaf from any leaf.
When this “version chain-tree” is used with the other components above, the “leaf objects” in this tree will just be the “snapshots” from above. The tree would grow from the lower left, starting with the green parent node of “L1”. Once that node is full, it will create its parent node, and then a new sibling which is the parent of “L4”. This pattern works recursively as the tree grows. This means the tree can support an unlimited number of items, and that as it gets exponentially large, the height of the tree doesn’t get much higher. With a sufficient width, you could fit reasonably any use case within a height of 3-6 I think.
Let me know where I can be more clear! And let me know if I’m fundamentally misunderstanding something about how Holochain works in practice.
And now, some questions I have for those with more experience:
- What’s a reasonable order of magnitude for the “cap” of how many links you can put on an entry in holochain? 10, 100, 1000? Curious as to how the version tree would realistically play out.
- I made sure (I think) that the data of entries is deterministic (monotonic? is that the word?) so that there are not two objects serving the same semantic purpose with different hashes, but one thing I’m not sure of is if multiple people create identical data. If I commit “Hello world” to the DHT, and you commit “Hello world” to the DHT, is that a problem?
