Just discovered InfoCentral (https://infocentral.org) :
A very interesting approach at the intersection of the #SemanticWeb AND the #DistributedWeb.
Perhaps you already know this work, …
… but I thought some aspects might interest the holochain community … … because both projects pursue the same goals
cool, thanks for the reading list recommendations! Holochain is definitely trying to tackle “location neutral”, “immutable references”, and “embedded semantics”… will have to read further to learn what the other properties are about!
What is really valuable in the InfoCentral proposal is a way to build a fully distributed web where the data architecture is totally decoupled to the software architecture. Is this also the case with Holochain ?
@bhaugen I don’t think semantic trees will ever find their way into Holochain… but perhaps Holochain will find its way into Ceptr. FWIU Holochain was originally envisioned as the data integrity layer for Ceptr, but it’s being spun off into its own project because it turns out it’s kinda useful on its own.
However, I love a challenge, and I think it’d be fun to implement semtrees/semtrex on top of Holochain Not that I have any time in the reasonable future…
Theoretically, yes. Holochain is deeply aligned with ideas like “Strong data semantics combined with content-based reference immutability” (quote from ‘Properties’ article). However we do have a way to go:
We’re still building Holochain and the core devs are into the “build the reference implementation and let that stand as the specification”. Holochain is two things: (1) a protocol for ensuring data integrity in a hash-addressed, peer-to-peer graph database, and (2) a framework that implements the protocol and provides an SDK to help you work with it. But the only thing that comes close to a specification is the working code itself. That’s very ‘agile’ (working code > documentation) but is sort of a barrier to people creating alternate implementations.
In these early days there aren’t a lot of patterns for interoperability with the many other hash-addressing-based data distribution layers out there (SSB, Dat, IPFS), which also have tightly coupled assumptions of their own (except IPFS). Holochain-the-framework comes with baked-in assumptions about how to move data around and how to control access to it. I feel bittersweet about this because I came of age in the early days of HTTP and interoperability was a given — a simple protocol, easily implemented and well supported. We are thinking about this — we’re supporting multihash, for instance — but there’s a lot of work to do to establish norms for data interchange among projects at all layers.
I really loved the ‘Properties’ document, by the way; it resonates strongly with what I love about Holochain. Mostly Holochain ticks all the boxes but there are some things that it’s either strongly opinionated about (e.g., data semantics and data access are tightly coupled, which sort of makes sense because a write or a delete is a subject to semantic constraints — who should be allowed to perform a write, and on what pieces of data?).
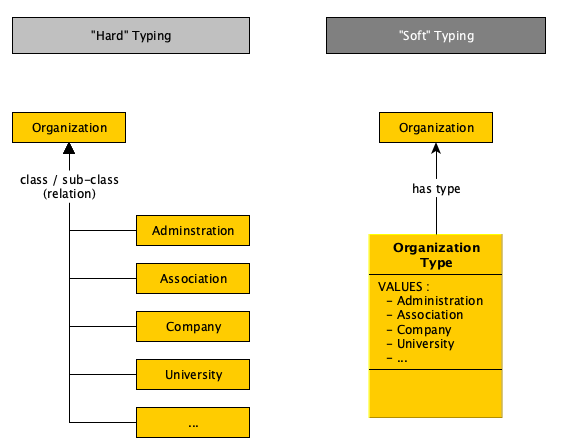
Just written a short « pitch » about a very important feature for my Entangled Bootstrap Repository (EBR) initiative … … which require to mix 2 apparently contradictory functional mode :
I think so, but I don’t understand why that is not a solution for mixing those functional modes. In every system we (@lynnfoster and I) have created, we have a mixture of a set of “hard-typed” classes (I seldom use subclasses anymore) and a set of “hard-typed” type-object classes that are used for user-defined soft-typing.
The hard types are defined by us (or rather by Bill McCarthy, but we inherited them from him) and the soft types are defined by the user groups as they need them.
BUT, Topincs has NO method to provide a way to « retrofit » at the Model level a new relevant #HardClass …
… based on specific description of some individuals at the Knowledge Base level !
=> That is what I’m calling Model-Discovery features (which are needed Model Reconciliation features)
I should clarify that I am discussing with you from a perspective that has classes and subclasses, but Holochain has moved on to Rust, which does not have such artifacts.
I have not personally moved on in my mind (I am still probably thinking in Smalltalk), but we should probly have somebody else re-interpret this discussion in an environment where neither classes or subclasses exist, but (I think) it is still possible to create type objects. @pauldaoust@pospi ?
It is true that I’m (only) reasoning in term of #Class …
. … as you could find in « O-O » (Object-Oriented) Languages or in SW Languages like OWL or Topic Maps
But, that should be a good news if Holochain-Rust (in the « Zome » level, I guess ?) …
… is « working with another - more flexible - paradigm that could allows to make « Reconciliation » easy
@bhaugen Unfortunately I’m not comprehending the discussion closely enough, but in the interest of either appearing intelligent or having someone intellectually wipe the floor with me (either of which is an acceptable outcome of my contribution), here goes!
It’s true that Rust doesn’t have subclasses. But structs are close enough to classes that you can consider them such for this discussion. They can have data and behaviour. If you’re already favouring composition over inheritance, Rust should be an easy switch because it enforces this.
A Holochain app imposes its own set of types on all the data that the zomes produce. It doesn’t have inheritance either. (Neither does an SQL database for that matter, I guess. Which is probably why data-layer classes in an app are pretty much separate classes that connect to each other via reference rather than inheritance.)
Maybe I don’t quite understand the whole field, but I feel like this sort of scenario is perfect for creating type objects as your links explain them. Indeed I can’t think of any other way to do polymorphism in Rust or Holochain.
This is a really interesting thread! I did want to touch base on the InfoCentral “technical properies of decentralised information” article, because I think the answer there is actually more nuanced than that.
I don’t see Holochain as satisfying those criteria natively- it’s too flexible. Until we have an application standard for RESTful data representation, we don’t have proper content-based addressing. In fact, in Holo-REA we have deliberately broken some of those constraints, for multi-network complexity reasons (hash-based addressing has complications, because IDs change).
Not to suggest that I think that’s good. There’s a user story we are missing a solution for, which I think could be addressed by realigning with some of these principles:
As a participant within a target network, I should be able to determine when an external record has linked into my network. I should also be able to determine when an external linker has not followed update protocol within my network- i.e. an external record has been updated (hash changed), but they haven’t notified my network of the update.
This could be achieved with metadata being included in responses, or a dedicated zome API for inspecting record versions. But ideally, if you request stale data from a network it would still return the data at that version, along with hashes of subsequent revisions that can be used to retrieve those versions. Currently in Holo-REA we have a persistent ID for a record between updates, because it was the easiest way of solving this user story at the time:
As a participant within a network, I should be able to determine how many distinct external records are linking to records stored within my network space.
I think proper handling of revision metadata and version-anchored hashes would allow us to have the best of both these worlds…
Quick note on Rust & OO: “traits” are the abstraction provided there, a bit like “mixins” in JavaScript, but with compiler guarantees instead of JavaScript’s looser duck-typing.
You can think of them a bit like multidimensional inheritance, where you can freely associate behaviours between different types of records without much restriction. Traits can also depend on other traits, to provide for an hierarchical arrangement of “trait inheritance”.

 Not that I have any time in the reasonable future…
Not that I have any time in the reasonable future…
 they were a neat idea, but not so maintainable in real life.
they were a neat idea, but not so maintainable in real life.