Acorn has a new release available within the latest Holoscape version.
Install v0.0.9-alpha
and open the “hApp store”. Make sure you read the associated instructions for installing, since it requires ‘admin’ access, unlike any other app. Don’t just click ‘Install’ right away.
Alternatively, install the standalone Acorn application, v0.3.3. Just download, unzip and drag to your ‘Applications’ folder, if you’re on a Mac.
Create a project, recommend Acorn to a friend too, so that you can get started collaborating on a project, by sending them a secret project invite code!
Fun fact, each Project runs within its own secret Holochain DNA, so that as long as your project secret is safe, you can guarantee all the data privacy that Holochain offers.
Marvellous! I’ve been waiting for a glimpse of people using the admin API to spawn/fork private DHTs. @Connoropolous do you feel like you’ve developed a pattern that’s ready to share with people? I looked for a bundle.toml to see how you’ve configured DNA vs instances but didn’t see one.
I am really happy to see the new release of Acorn, great job.
Can I invite you to Virtial Hacklong (tech meeting once a week) that you can demo Acorn and share your best practices of holochain to others? (people in the group are tech guys and mostly developers)
Hi @hedayat, thanks for the invitation. I’m going to decline for now, I am intending and wanting to share lessons learned though so I am planning to write a blog post about that. I will share it when it’s ready which shouldn’t be long!
That’s to @pauldaoust question to in fact.
I brought it (dna spawning, with uuid) up a little bit in discussion on app modularity with @pospi and @guillemcordoba here
it links into code too, from this second comment.
hc-redux-middleware (forked and with a few minor tweaks) worked nicely, since it already had a createHolochainAdminAsyncAction function / redux action creator.
It made me realize how that is an interesting, and somewhat challenging aspect of Holochain DNA spaces, is that by ‘entering the space’, people don’t really have any way of knowing inherently whether anyone ‘entered the space’ before them. The only way they can know is by looking for a piece of data that everyone who joins the space can expect to exist. If it exists, someone entered the space before you, if doesn’t, we might (but shouldn’t necessarily) assume no one did.
a thing that can exist in isolated and independent “islands” at its incarnation, and is distributed, might be considered to have no beginning and no end, haha.
Nice to see this! I’m planning on building a small zome that keeps track of all the dnas cloned from an existing template, to list them when you have not joined them yet. @Connoropolous have you already done something like this, and would it be useful to you?
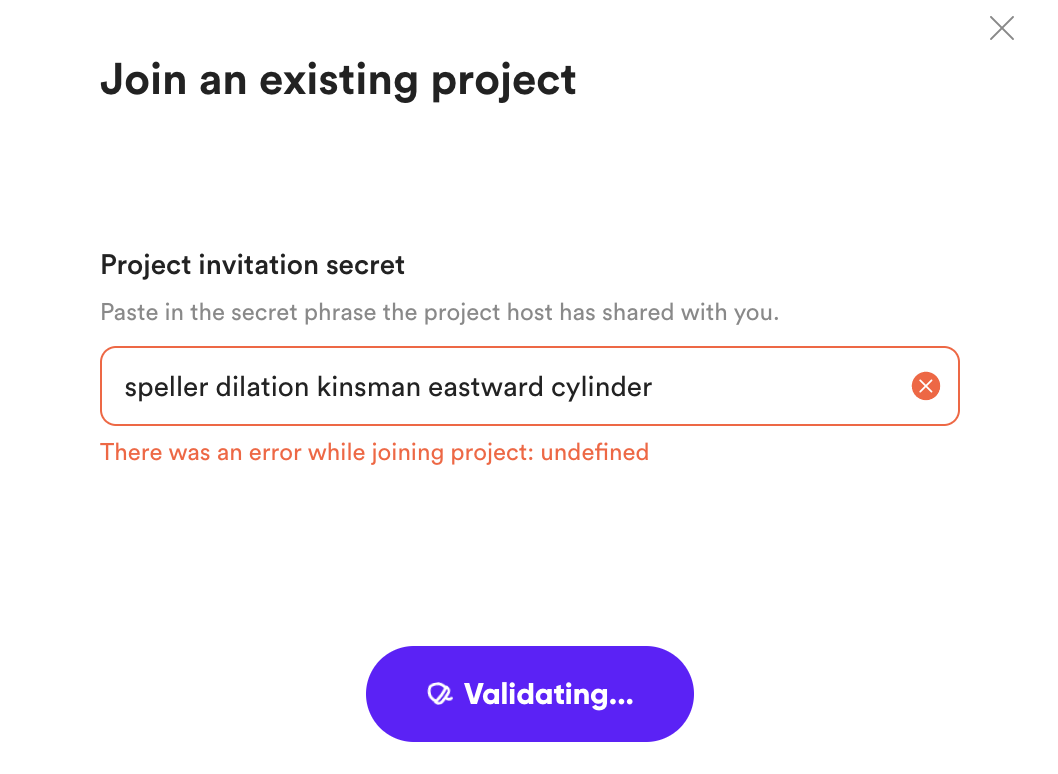
That is a not helpful error, darn
However, I have one theory, which is based on something not immediately intuitive.
Each time a new person joins a project, it gets easier for new people to join the project. Here’s why: in order for someone to join a project, they actually need to verify immediately that someone else has actually created this project, and that means checking information that they committed to their chain.
So when the second person to join attempts to join, the first person who created the project needs to be online/connectable at the time.
So in those cases, it is best to coordinate a time when joining will happen.
After the second person has joined, only one of the first two people needs to be online when the third person joins, etc. Making it exponentially more likely that coordination between someone new joining needs to coordinate with an existing project participant about a time to join.
I am starting to think about an alternative to that, now that I’ve walked through it. But it will require rethinking more.
Hum interesting… How are you managing a new member joining a project? With capabilities tokens of some sort? Are you preventing non-invited agents to join somehow?
Just curious about what patterns you are using, since with the mutual-credit app we are also beginning to play with multi-dnas and membranes around them.
whoever gains access to the invite code for a project has the ability to join that project.
This is dictated by deterministically converting the secret into a UUID that gets placed in the DNA, and produces the same DNA hash address as the other players are playing in.
The catch to all this is that when a player actually attempts to join a DNA, it acts like a two way in and out flow, where it actually tries to join the DNA, it checks if that DNA exists as indicated by the presence/existence of an entry anchored to a predictable address that everyone knows. If no “project_meta” entry exists anchored to that anchor, then it reverses out of the DNA, and suggests that no such project exists. That’s why new project joiners require an immediate connection to an existing player.
without that"project_meta" being returned to the project joiner, that individual doesn’t know the name or image, etc of the project it is attempting to join, because that is stored in the DHT, that it hasn’t yet synced with.
I am considering the alternative now though, where we could store a list of “projects pending to be joined” … where it will just join it, and then wait for a prolonged period to see if it ever syncs with, and joins other nodes. In other words, don’t reverse out… just occasionally check back in to the DHT and see if any other nodes come online and provide access.