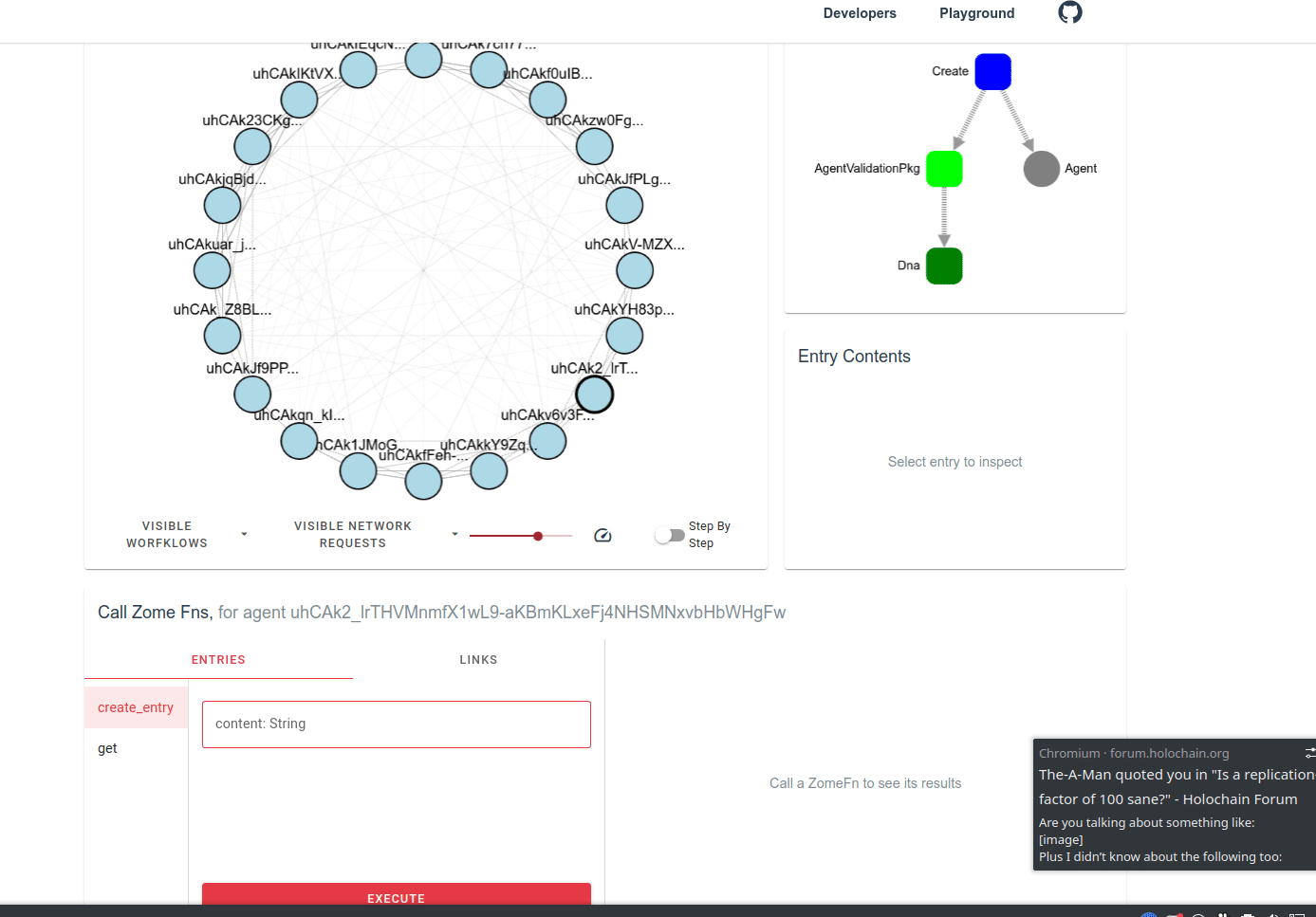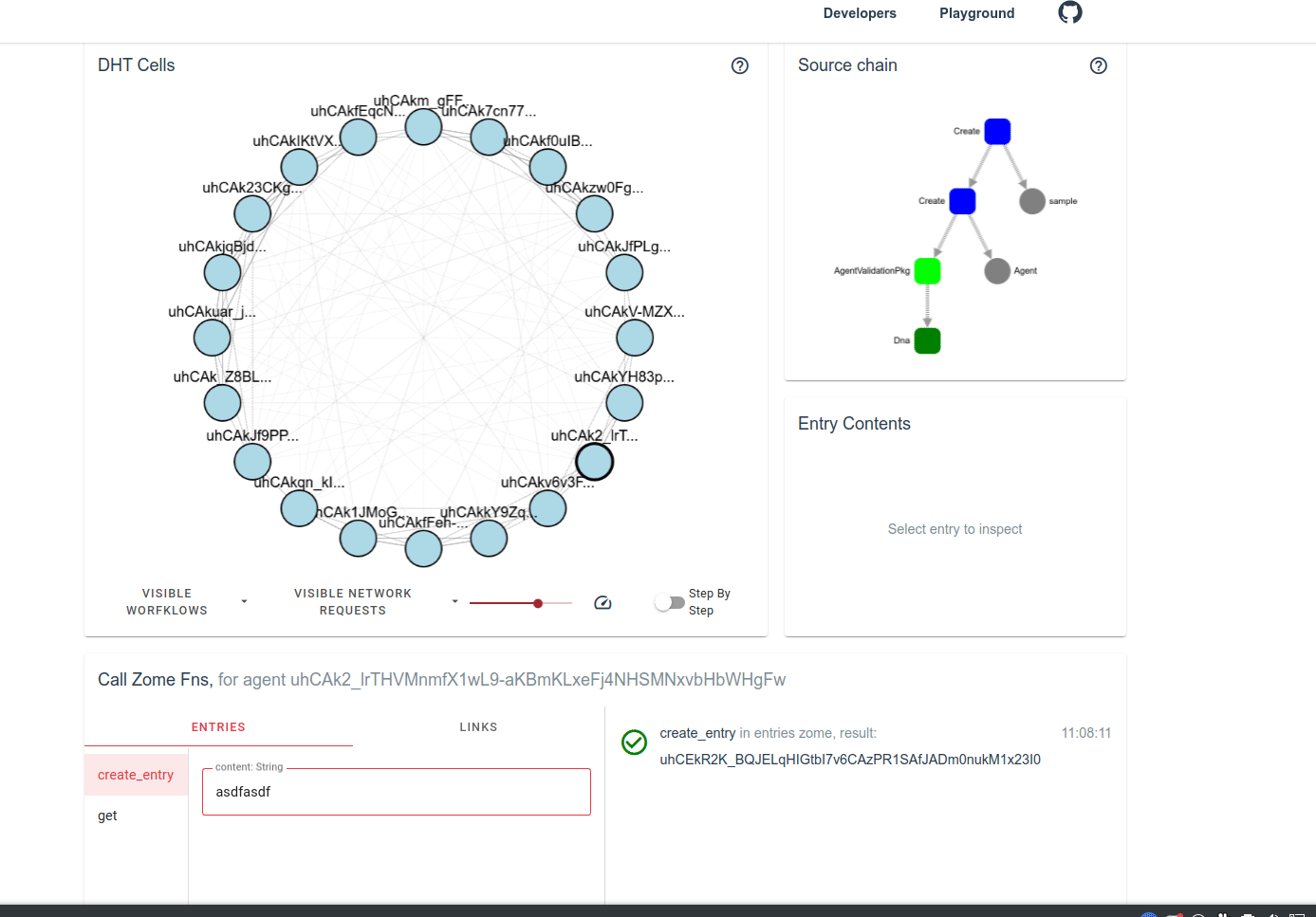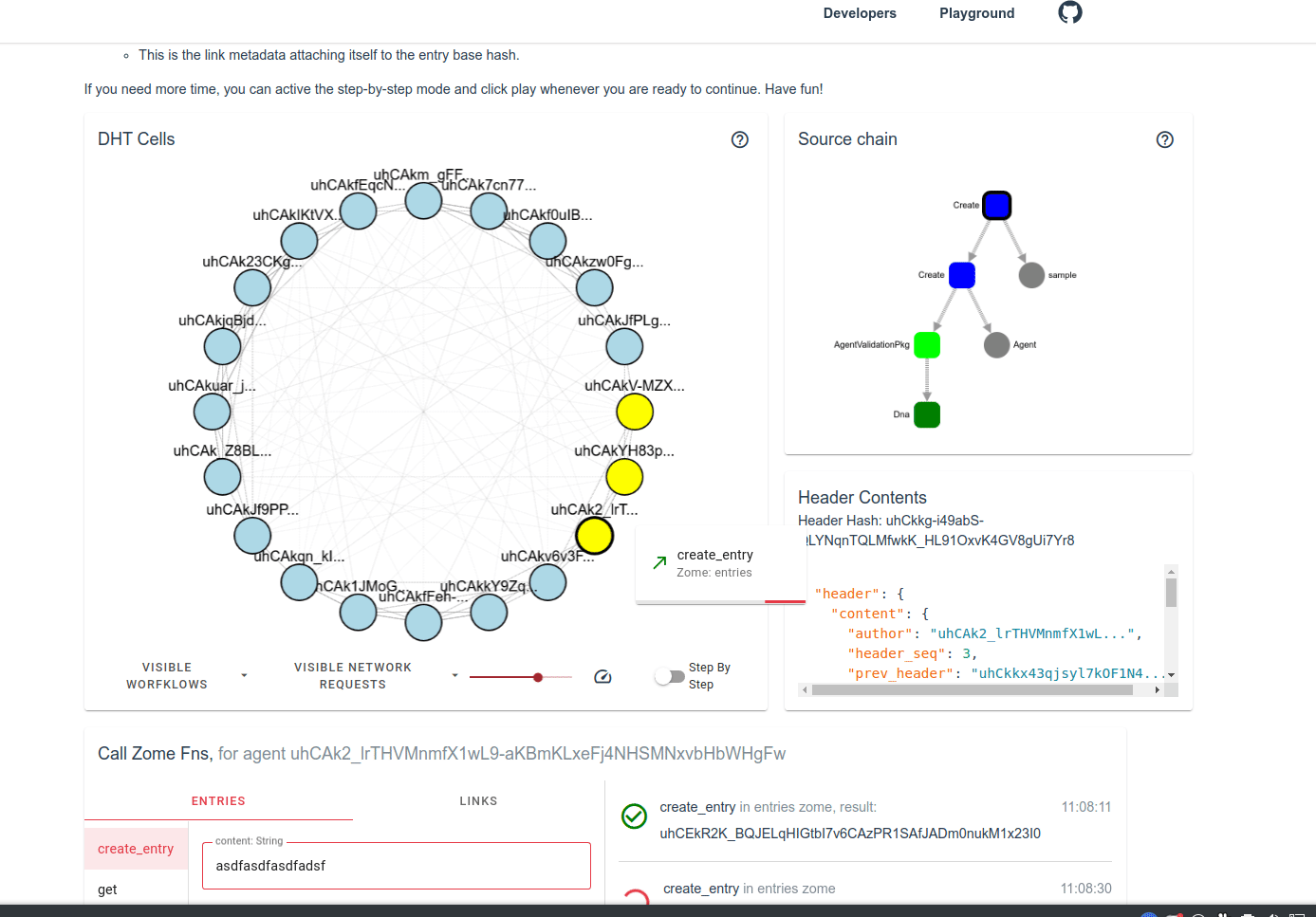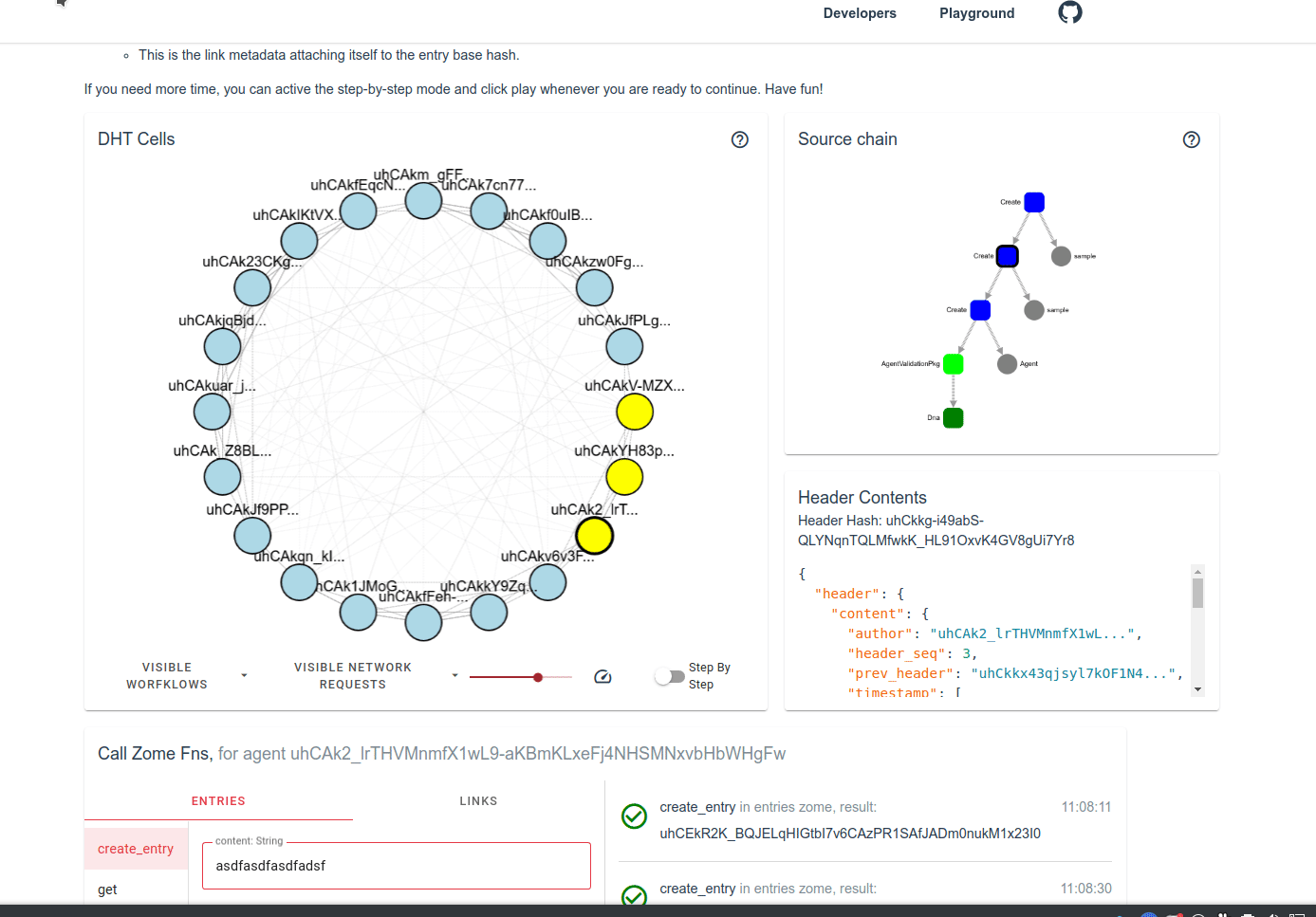
on more storage redundancy = more security = safely facilitating higher value transfers:
to make sure i understand the premise i will restate it to try and steel man it:
- sybils can brute force arbitrary keys
- so can position themselves arbitrarily close to any given entry on the DHT
- so can brute force arbitrary validation
- nobody else will run the validation so it will be accepted
And yes, in a purely theoretical sense this is true, but there are several mitigations.
- sybils cannot produce arbitrary public keys.
sure they create arbitrary private keys, but working backwards from a desired public key to a private key is equivalent to breaking the underlying cryptography.
getting arbitrarily close to a given key is analogous to the difficulty factor in proof of work, brute force will only get you so far
- inorganic networks are detectable and false positives are safe
every agent can measure and calculate the relative tightness of the agents clustered around any particular datum and compare it to the network norm
if sybils brute force themselves to 10, 100, 1000x etc. the organic distribution (which is cryptographically guaranteed to be evenly spread) of the rest of the network, we can detect that and be suspicious.
being suspicious means we could opt in to running validation ourselves to double check a high-value transaction against what the anomalous cluster is telling us, if we agree, no harm, no foul
an overly tight cluster that appears organically should heal itself through gossip over time
the tight clustering is a mathematical relationship between the public keys and entry hashes, so doesn’t require any particular data storage redundancy to detect
- only one honest agent is needed to confound many sybils
for deterministic validation, as a recipient we can treat any discrepancy as highly suspect, we know that at least one node is compromised or in error, and we immediately look to warrant someone(s)
if the sybils just try to ‘brute force a little bit’ to evade the tight cluster anomaly detection (above) they don’t really achieve much, as they have to be closer to a given entry than all other network participants now and in the future
this is also the reason why trying to brute force an entry hash won’t achieve much, because that simply moves it to a different location within an evenly spread network of otherwise honest (or at least not colluding for this entry) agents
- the network has membranes
the heuristics above rely on overall network size, it is true that a small network with very few honest participants is going to be easier to sybill based on a generic algorithm
however, small networks typically also have stronger membranes to entry
consider a chat room between friends, the humans behind the machines already know their friends and a sane GUI will show to the humans who is in the chat room
one problem with the server based approach is that clients of the server do not know who has access to the server, but the peers on a network who are trusting each other with validation do know who each other are, it’s not possible to say that we can see someone for the purpose of validation but we cannot make their presence known to the human using the happ
mechanical membranes like auth tokens, cryptographic challenges, etc. can be coded into smaller networks to prevent sybils
elemental chat works this way already, we have a social membrane protecting the relatively immature systems while we continue to build them out 
- every agent can opt-in to validation
if we wanted to create an opt-in validation for specific entries, such that it is performed on every get (then likely cached locally), we could do this
we aren’t doing this because it’s quite a big hammer (would slow things down too much to be default behaviour at least), but it could be done if there was a real need for it
note that you can simulate this yourself as a happ dev by running the validation callbacks against data you get (because validation callbacks are regular functions) explicitly after you get it - you’ll just need to do the legwork for any dependencies
i wouldn’t recommend this normally, but it is an option for the paranoid
- recursively tight clusterings are non-linearly suspicious
ok, so let’s assume you manage to pull off a single tight cluster around an entry without detection
in the case of typical value transferal systems (e.g. a ledger) your transaction comes at the end of a long line of transactions back to the genesis of the system
the suspiciousness of 2, or 3, or N tight clusters that depend on each other is exponentially more suspicious than a single cluster on its own, this is a way bigger red flag than two unrelated tight clusters, if an agent ever sees chained clusters it should probably immediately start trying to warrant someone(s)
- agents don’t need to ask the absolute closest agents to the data they want
agents only need to ask someone close enough to the data that they can function as an authority, we don’t have to try and boot out authorities to get ‘the most authoritative authority based on closeness’
network partitions mean there can never be a perfect list of who is the exact authority for something globally anyway
some looseness here allows for some natural randomness that helps flush out sybils, and we only need to hit one honest participant
a sybil can squeeze themselves arbitrarily close to some entry but it doesn’t actually guarantee that 100% of all network traffic will be routed to them for that entry
- humans are part of the equation
ok, so you’re doing a high value transfer… to who??
scammers are gonna scam
the network can apply algorithms to detect people breaking validation rules to some degree of confidence (even proof of work is statistical) but at some point effort is better spent to help humans contextualise their transactions
ironically and sadly, the irreversible nature of blockchain makes it a natural breeding ground for scams
not that i want the ability to rollback blocks, but making a transaction 0.0001% more ‘final’ has diminishing returns vs. making a human 10% less likely to send money to paypel.com instead of paypal.com
- there are other heuristics that can detect sybils
beyond mathematical clustering of keys, a smoking gun for a sybil is that they tend to only participate in a network to the absolute minimum they can get away with in order to be a sybil
what this means is going to be app specific, but for example:
- being wary of authorities with relatively little activity of their own
- being wary of agents many degrees of separation away from the agents you usually interact with (web of trust)
- being wary of agents with very small arcs (low effort resource-wise)
- being wary of a cluster of agents with similar keys all created in a similar timeframe or joining the network at a similar time when there was not a spike in new users with different keys