Really enjoying the clarity that is coming through in this thread of late… hopefully I can add some more pieces to ground this (:
Other than what follows, in agreement with everything else being said here. And really appreciate the clear distillation from @zeemarx_jeremyboom8 of some of the common abstract logic at play. Validating to see the thinking here aligned with some of the fundamental insights I remember people in the blockchain space coming to as they developed programmatic governance systems (“multisig is a fundamental abstraction”).
group agency
An overlap here is “group accountability”, and it’s all intertwined with the mechanism for how to act “on behalf of” the group. Given that groups have no native agency in Holochain this means that abstractions for representing groups must be created, and APIs must be made manually compatible with them. So it will be up to each Holochain app whether it allows the participation of group agents or not. In terms of technical details, we think this requires onBehalfOf parameters at the zome API layer.
This means we need a standard set of APIs for dealing with groups. In REA, group agents can do anything that singular agents can do. So, any references to Holochain agent IDs also need to be able to reference group agent IDs. We think this necessitates a Holochain URI scheme- the document linked in this issue proposes a format which we believe allows us to elegantly differentiate agent, entry and DNA addresses.
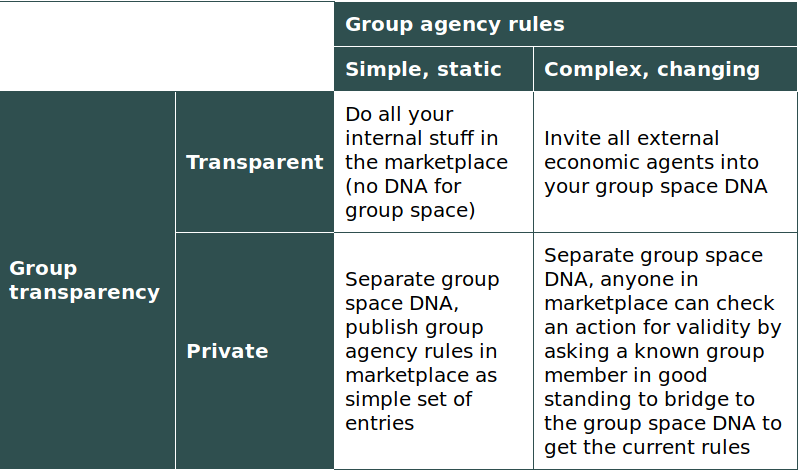
We’re not sure what “group agent IDs” actually are in terms of Holochain’s fundamentals; but I think they’re probably DNA hashes. It makes the most sense to me from an encapsulation perspective to use permissioned DNAs to represent group agents; bridge them to other DNAs that the group needs to interact with; and internally code them with whatever governance rules the group wants to use (we have some suggestions, but they imply the development of that standard set of APIs to interrogate group agent DNAs for privileges).
You would end up with paired DNAs which store the group configuration data, and library crates which provide the API for other DNAs to make checks against the group’s membership and authority. Note that in this case we are talking about other DNAS, not other zomes- integration of something like this probably isn’t tied to a particular network, but interacts with many. So the interface would likely be via hdk::call rather than the internal entry & link manipulation API.
“checking with the group” pattern vs “ignorant DNA” pattern
(not a reply, just a heading :P)
The above is one path we could take, but it feels like a failing of “separation of concerns”. It would be cleaner if modules wanting to support group agents mostly didn’t have to think about the logic of group agents at all. The other path is to use the group agent as a controller DNA that mostly just manages capabilities in other DNAs. We described this as 2 complementary zomes which go together to form an “agent relationships” DNA.
Basically, there may be a lot of cases where groups are about delegating individual members to do different things. In these cases, the group could just be coded to delegate capability tokens to its members. More advanced cases, eg. where groups have “role based access control” internally, would potentially require other DNAs to inspect the group in order to verify authority. So I think it’s likely a mix of these two techniques.
Regardless, you still need to pass in onBehalfOf and deal with it if you want your modules to track the groups who’s authority was used to perform certain actions.
It’s for this reason that I believe this module needs to be treated as Holochain core infrastructure, and care given to standardisation and ease of adoption. Incompatible group agent implementations means incompatible hApps.
“orphaned resources” and continuity
I’ve recently put some thoughts together about what splitting out sub-projects might look like. For public and permissioned, discoverable sub-projects, you could certainly go down the path of running “headless nodes” to keep the DHT alive. But I think that’s a bit hairy.
You could make it less hairy for the parent org by registering sub-project members and network IDs within the organisation’s collaboration space. That way, at least you have a record of who was involved and can correlate any dangling group agent IDs with those people if the group has been taken offline.
Next level would be translating & replicating entries from the sub-project network into the main network. It’s essentially data duplication, but that’s not necessarily a bad thing in distributed environments with semi-permeable access membranes. For REA networks this is a per-record setting; because economic participants can enter event observations scoped for publication in many accounting scopes. Say for example the sub-project needs to enlist the skills of another worker from the group’s collective- they could publish an Intent into the sub-project that is also broadcast into the wider network’s skills marketplace so that a contributor can be located.
At the end of the day, there’s nothing you can really do about people creating entirely private groups that your parent collaboration space has no knowledge of. But at the very least we can create tools to facilitate easily “spinning off” projects in ways that are coupled with the “parent” collaboration space where the goal is to keep them connected. But you want loose coupling, because you want the sub-projects to be able to expand into collaboration with others outside of their originating organisation.
Ok, I’ve said a lot. Am I getting us closer to an MVP, or am I adding extra complexity? What do we pare all this back to?



 )
)